 Volume
2, Number 1, 2015, 55–66 journal homepage:
region.ersa.org
Volume
2, Number 1, 2015, 55–66 journal homepage:
region.ersa.orgA multi-level path analysis of social networks and social interaction in the neighborhood
1 Eindhoven University of Technology, Eindhoven, The Netherlands (email: p.e.w.v.d.berg@tue.nl)2 Eindhoven University of Technology, Eindhoven, The Netherlands (email: h.j.p.timmermans@tue.nl) Received: 25 August 2014/Accepted: 1 April 2015
Abstract. Neighborhood-based social interactions have gained attention as a research topic in recent decades in light of urban policies that aim to improve livability in urban areas. Social interactions are anticipated to play an important role in neighborhood livability; however, empirical studies investigating the extent to which neighborhood characteristics can improve social contacts among residents are scarce and inconclusive. Therefore, this paper studies the role of socio-demographics and neighborhood characteristics in the formation of social network ties and social interactions with neighbors. These relationships are analyzed using a multi-level path analysis approach based on data collected in 2011 from a survey of 751 respondents in 70 neighborhoods of Eindhoven, the Netherlands. The results indicate that neighborhood-based contacts are influenced by personal and household characteristics, such as education, income, work status, ethnicity, household composition, and years at the current address. The effect of neighborhood characteristics is limited, and only one significant relationship was found – between neighborhood income and the number of neighbors in the network. This finding is inconsistent with the assumption that an adjustment of neighborhood characteristics can lead to increasing social interaction among neighbors.
Key words: Personal networks, multi-level path analysis, neighborhood, social contact
1 Introduction
The rapid development of mobility tools, including transportation modes and communication technology, characterize recent decades. These tools have expanded the range over which people perform their activities and enable contact with friends and relatives living far away. The ability to maintain social networks over greater distances raises questions about the relative importance of local social contacts. Subsequently, local social networks are believed to have lost importance over time (e.g. Wellman 1979, 2001, Guest, Wierzbicki 1999). Thus, it is important to investigate to what extent local social interactions still take place.
Sociological literature contains a rich amount of studies on the degree to which social networks are neighborhood-based. Some studies concur that neighborhoods’ roles in significant social ties are declining (e.g. Wellman 1979, 2001, Guest, Wierzbicki 1999). Others argue that contacts with neighbors remain important and are increasing (e.g. Mollenhorst et al. 2009, Mollenhorst 2014). By studying changes in the role of neighbors in Dutch personal networks between 2000 and 2007-2008, Mollenhorst et al. (2009) find that local contacts became more important. In a subsequent study, Mollenhorst (2014) concludes that between 2007-08 and 2013, next-door neighbors again gained importance, especially for practical help, such as odd jobs in and around the house.
Additional literature suggests that neighbors tend to play an important role in practical and social support. Bridge (2002) suggests that many people still value contact with their neighbors, as they are often a source of assistance. Although neighbors comprise a small proportion of an individual’s social network, their contact frequency is relatively high. Neighbor relations are typically weak (e.g. Granovetter 1973, Fischer 1982, Van der Poel 1993); however, they are important for individuals’ resources and for creating a sense of community and social cohesion (Granovetter 1973).
Contact with neighbors advances a sense of “home” (Bridge 2002). Thus, social contacts among fellow residents are an important factor of livability in neighborhoods. In recent decades, the topic of neighborhood-based social interactions has gained attention in western European housing and urban planning fields in light of urban renewal policies (Forrest, Kearns 2001). These policies aim to deal with a variety of urban problems such as quality of housing and public space, unemployment, poverty, and livability. In these policies, social interactions are expected to play an important role in managing such problems.
Although several researchers have studied local social contact, empirical evidence of the effect of neighborhoods’ (spatial) characteristics on social interaction among residents is scarce and inconclusive (Atkinson, Kintrea 2001, Kleinhans 2004, Galster 2007, Pinkster, Völker 2009). However, these characteristics are of special interest from a housing and urban planning context. This paper therefore aims to contribute to the knowledge of neighborhood-based social contacts by studying to what extent socio-demographics and neighborhood characteristics contribute to social contacts among neighbors. These relationships are studied using a multi-level path analysis approach. The analysis is based on data collected in 2011 from a survey of 751 respondents in 70 neighborhoods of Eindhoven, Netherlands.
The following section describes the literature on factors influencing neighborhood-based social contacts. Section 3 presents the data collection and descriptive statistics. In Section 4, the path analysis results are presented. Finally, Section 5 contains the conclusions and discussion.
2 Factors influencing neighborhood-based social contacts
Literature suggests that neighborhood-based social contact may be affected by characteristics such as income (which has been shown to correlate with socio-demographics such as ethnicity), urban density, and residential mobility. For example, in Fischer (1982)’s survey of personal networks in Northern California, he finds that contact frequency between neighbors is lower in low-income neighborhoods than in higher income neighborhoods. According to Fischer, greater variety in race, ethnicity, and occupation in low-income neighborhoods can explain this difference. This suggests that a similarity in socio-demographic characteristics enhances neighborhood contacts (Völker, Flap 2007), which contradicts the assumption that social diversity would lead to more neighborhood-based social interaction.
Comparing the role of local relationships and social support in a low-income and a socioeconomically mixed neighborhood, Pinkster, Völker (2009) find that those living in the low-income neighborhood have fewer resources in terms of accessed prestige (i.e. social network members in prestige-rich jobs). However, they find no difference regarding social support for dealing with everyday problems.
Studying the effects of social-structural neighborhood characteristics on the relative size and the composition of neighboring networks of elderly people in Dutch neighborhoods, Thomése, van Tilburg (2000) find that neighborhoods with a larger degree of urbanization have a smaller proportion of neighbors in their social network. This is in line with Fischer (1982)’s findings suggesting rural dwellers are more dependent on local social contacts and have more neighbors in their social network.
Thomése, van Tilburg (2000) also find residential mobility (the number of residents leaving the neighborhood per year, per thousand inhabitants) is associated with smaller neighboring networks.
The close proximity of amenities is also expected to increase opportunities for social interaction among residents (e.g., Oldenburg 1989, Talen 1999, Völker, Flap 2007, Dempsey et al. 2012, Francis et al. 2012, Hickman 2013, Van den Berg et al. 2015). Shops and supermarkets, schools, parks, and community centers have been found to be particularly important in this respect.
In addition, network localness – the extent to which one’s social network is neighborhood-based – has been found to be associated with personal or household characteristics such as socioeconomic status. For example, Van den Berg et al. (2015) find men are less likely to interact with a local tie (someone living within 1 km) than women are. Age may also relate to neighborhood orientation: older adults are considered as being particularly dependent on neighboring networks. Völker, Flap (2007) indeed find that older people are more likely to have neighbors in their social network. Likewise, Van den Berg et al. (2015) find that older people are more likely to interact with fellow residents. Conversely, Thomése, van Tilburg (2000) did not find age to affect the proportion of neighbors in people’s social network.
Fischer (1982) finds social networks of low-income, low-educated, and minority residents tend to be more locally oriented. This relates to the cost of activities and transport, which results in a smaller action radius for those with a lower income (Van Beckhoven, Van Kempen 2003). Level of income is associated with characteristics including work status, level of education, and ethnicity. Van Eijk (2010) finds that low-educated people have a larger share of local ties in their network; however, the number of local ties was similar. For higher-educated people, the number of non-local network members was higher. On the other hand, Van der Poel (1993) finds that higher-educated people have more neighbors in their networks than lower-educated people. The study by Van den Berg et al. (2015) did not show significant effects of income or education on the likelihood of a social interaction taking place with someone living in the neighborhood.
Time spent in the neighborhood increases the chances of meeting neighbors (Guest, Wierzbicki 1999, Völker, Flap 2007, Van den Berg et al. 2015). There are different conditions that cause people to spend more time in the area where they live. For example, people who do not work are likely to spend more time at home than people who work full time, as are people with young children. Additionally children’s schools can serve as a setting to develop and maintain locality-based ties (Van Beckhoven, Van Kempen 2003, Van Eijk 2010). Völker, Flap (2007) also find the presence of primary schools to increase the likelihood of including neighbors in the personal network.
In addition, car ownership might also affect the time spent in the neighborhood and the frequency of interacting with neighbors, as a car provides opportunities to interact at larger distances, outside the neighborhood. Kowald et al. (2013) find that car owners have social network members who live further away. Similarly, in a previous study we found that social interaction with a local tie is less likely for people with more cars in the household (Van den Berg et al. 2015).
Length of residence is also likely to affect social contacts with neighbors. Hipp, Perrin (2009) and Van den Berg et al. (2015) find a longer residence in the neighborhood increases neighborhood-based social contacts. In addition,Van den Berg et al. (2015) find that people who feel “completely at home” in their neighborhood are more likely to interact with local alters.
In a previous study, we also found that involvement in clubs or voluntary associations results in a larger social network (Van den Berg et al. 2012). As clubs are often locally based, this may indirectly increase the frequency of contact with neighbors.
Finally, the degree to which people have neighborhood-based social contacts might also be related to their extra-neighborhood contacts. Völker, Flap (2007) argue “if one has no other members in their personal network, neighbors become the first (and only) choice.” However, Van Eijk (2010) concludes “resource-poor people with small networks do not seem to compensate for their small network by forming more ties with fellow-residents.”
This brief overview of literature suggests that neighborhood-based social contact may be related to a number of neighborhood and personal characteristics. However, the results from different studies are inconclusive. Thus, additional empirical evidence is needed to understand the effects of personal and neighborhood characteristics on social interaction with neighbors.
Based on the discussed literature, we hypothesize that the frequency of interaction with neighbors is higher for people with more neighbors in their social network. The number of neighbors in the social network is, in turn, likely to be affected by the total social network size. The following personal characteristics are hypothesized to affect social network size the number of neighbors in the social network, and the frequency of interaction with neighbors: gender, age, work status, income, education, household composition, car ownership, involvement in clubs, and perception of the neighborhood. The following neighborhood characteristics are hypothesized to affect the number of neighbors in the social network and the frequency of interaction with neighbors: neighborhood income, urban density, housing tenure, residential mobility, ethnicity, household composition and age in the neighborhood, and distance to several amenities (restaurant, school, supermarket, highway, and train station). This study will analyze these relationships based on data collected in Eindhoven, Netherlands.
3 Data collection and descriptive statistics
The data used for this study were collected in May 2011 in 70 of Eindhoven’s 109 neighborhoods. Neighborhood selection was based on the number of inhabitants, leaving out neighborhoods or districts with low numbers of inhabitants such as industrial areas, the university campus, and the airport area. A stratified sampling technique was used. The city was divided into neighborhoods (based on the arrangement of the municipality), in which equal numbers of individuals were contacted. The addresses within these neighborhoods were chosen randomly.
People aged 18 or over could participate in this study. To recruit respondents, a personal approach was employed by visiting them at home. If residents were not at home, the addresses were skipped. The visits took place at varying times of day, including the evening, to prevent an underrepresentation of working people. The personal approach was employed to increase respondent’s participation; however, it may have caused some bias in the sample, as we hypothesize that time spent in the neighborhood (and at home) strongly relates to social contact with neighbors. In total, 751 useful questionnaires were collected.
The data collection instrument consisted of a survey on quality of life aspects of individuals in the area where they reside. Several socio-demographic variables were collected in the questionnaire. In addition, neighborhood characteristics were obtained from Statistics Netherlands (CBS 2012). Table 1 shows the sample characteristics. The results show that the sample is representative of the population with respect to gender. With respect to age, the sample is fairly representative: 26% of the sample is between 18 and 34 years of age as opposed to 33% in the population. 58% are between 35 and 64, and 16% are 65 or over. 58% of the respondents work part-time or full-time. 11% have a low income and 7% have a low level of education. When compared to the population of Eindhoven, low-income and less-educated people are somewhat underrepresented, which is common for this type of survey. Two-fifths of the sample lives in a household with children, and two-thirds are member of one or more clubs. Regarding neighborhood characteristics, Table 1 shows that the sample is representative of the population with respect to neighborhood income, ethnicity, and urban density.
| Characteristics | Sample % | Eindhoven % | |
| Personal characteristics | |||
| Male | 49 | 51 | |
| Age 18–34 | 26 | 33 | |
| Age 35–64 | 58 | 47 | |
| Age 65+ | 16 | 20 | |
| Works | 58 | 65 | |
| Low income: <€1000,- per month after tax | 11 | 20 | |
| Primary education | 7 | 25 | |
| Household with child(ren) under 18 | 40 | 27 | |
| Member of a club | 65 | 61 | |
|
Neighbourhood characteristics | Sample | Standard | Eindhoven |
| mean | dev. | mean | |
| Mean household income (× €1000) | 23.91 | 5.66 | 23.2 |
| % non-western immigrants in neighbourhood | 16.34 | 9.02 | 17.9 |
| Urban: >2500 addresses per km2 (%) | 39 | 38 | |

The aim of this paper is to study the role of socio-demographics and neighborhood characteristics in the formation of social network ties and social interactions with neighbors. In the analysis, three dependent variables are used: social network size, the number of neighbors in the social network, and the frequency of interaction with neighbors.
Figure 1 shows the question that was used to measure social network size and the number of neighbors in the social network. This method used to gather the characteristics of the respondent’s social networks is known as the summation method see (McCarty et al. 2000) for details. Social network size is the sum of very close and somewhat close alters in all categories. The number of neighbors in the social network is the sum of the number of very close and somewhat close neighbors. Note that closeness here refers to emotional closeness to reflect the strength of the tie between ego and alter.
On average, respondents have a social network size of 24.85 people. The average number of neighbors in the network is 2.80. This means that the average percentage of neighbors in the respondents’ social network is 11%. Although the size and composition of networks depend on the name generating questions that are used, neighbors generally constitute 8% to 16% of a person’s social network e.g. (Fischer 1982, Van der Poel 1993, Völker, Flap 2007, Van den Berg et al. 2009)
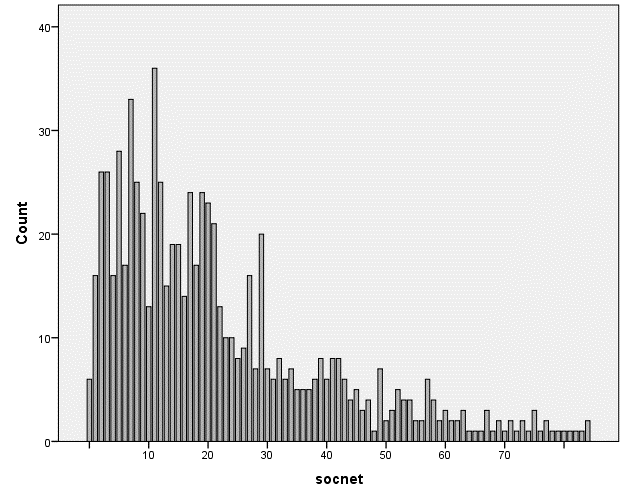
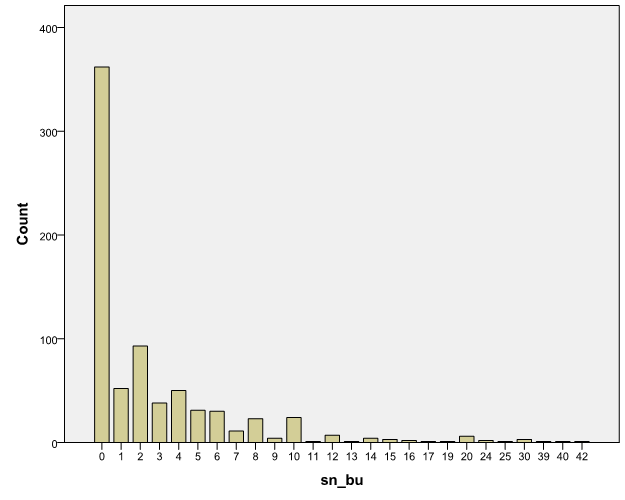
Almost half of the respondents recorded no neighbors as social network members. This finding is in line with Bridge (2002) and Völker, Flap (2007) who report that 48% of the respondents in their studies have no neighbors in their social network. Note that the question used in our survey does not allow for overlap between the categories. For instance, relatives or co-workers who also live in the same neighborhood will probably not be recorded as neighbors.
Moreover, not considering neighbors as social network members – as defined by the name generators – does not mean these people never interact with their neighbors. As can be seen in Table 2 only 6.5% of the respondents indicated they never interact with their neighbors. Respondents who interact with their neighbors several times per week represent the largest share of responses for this question.
Although contact frequency was measured on an ordinal scale, in the model it is treated as a continuous variable, with values 1-6 (a higher number corresponding with a higher frequency) corresponding to the response categories used in the questionnaire. This results in a logarithmic scale.
| Frequency of interaction | N | % |
| Never (1) | 49 | 6.5 |
| Once a month or less (2) | 112 | 14.9 |
| 2 or 3 times per month (3) | 89 | 11.9 |
| Once a week (4) | 130 | 17.3 |
| Several times per week (5) | 237 | 31.6 |
| (almost) every day (6) | 133 | 17.7 |
4 Methods and results
Our research question requires a method that can capture the relationships between several dependent and independent variables. Path analysis is a method that meets this requirement. Using path analysis, the effects of the explanatory variables on the dependent variable and the relationships between the dependent variables can be estimated simultaneously. In path analysis, both direct and indirect effects can be calculated.
Path analysis is a special case of structural equation modeling (SEM). Whereas SEM can deal with measured (or observed) variables and latent variables (also known as factors, constructs or unobserved variables), path analysis only deals with measured variables. In this study, we use path analysis because the variables all refer to characteristics or behavior that is observed.
We estimate a multi-level model taking account of the hierarchical structure of the data (respondents are nested in neighborhoods). Whereas a single-level model treats the respondents as independent observations, a multi-level model treats the respondents that belong to the same neighborhood as clusters by allowing for residual components at each level. For an in-depth review of multi-level (structural equation) models, we refer to Hox, Roberts (2010).
The path analysis model is estimated using the statistical software package LISREL (Jöreskog, Sörbom 2001). Despite non-normality in the data, the maximum likelihood method is used to estimate the model. Correlation of exogenous socio-demographic and neighborhood characteristics is allowed in the model. As a first step in building the model, all paths from the exogenous variables to the endogenous variables, as well as paths between the endogenous variables, were entered. Relationships that were not significant at the 0.1 significance level were removed in a stepwise procedure. This resulted in the final model. The unstandardized coefficients of direct and total effects of the final model are shown in Table 3. The total effects are the direct effects (X causes Y ) plus indirect effects (X causes Z, which in turn causes Y ).
The goodness of fit statistics of the model are shown at the bottom of Table 3. The overall fit of both models is moderate. Chi-square divided by the model degrees of freedom has been suggested as a useful measure and conventions suggest that for correct models, this measure should be smaller than 2 (Golob 2001) or at least smaller than 5 (Washington et al. 2003). According to this criterion, the model has a moderate fit with a value of 6.87. Another goodness of fit measure, which is based on the chi-square, is the root mean square error of approximation (RMSEA), which measures the discrepancy per degree of freedom. The value should preferably be less than 0.05 (Golob 2001). The RMSEA of 0.13 also suggests that the model has a moderate fit to the data.
| Multilevel path model
| ||||
| number of | Interaction
| |||
| Network size | neighbours | frequency
| ||
| in network | (1–6)
| |||
| Network size | Direct (t) | 0.12 (21.03) | ||
| Total (t) | ||||
| Number of neighbours in network | Direct (t) | 0.08 (6.54) | ||
| Total (t) | ||||
| Age | Direct (t) | -10.21 (1.78) | ||
| (logarithm) | Total (t) | -10.21 (1.78) | -1.22 (1.77) | -0.09 (1.71) |
| Full time work | Direct (t) | -0.44 (3.42) | ||
| (>36 hours/week, dummy) | Total (t) | -0.44 (3.42) | ||
| Low income | Direct (t) | -0.43 (2.30) | ||
| (<€1000,- net/month, dummy) | Total (t) | -0.43 (2.30) | ||
| High income | Direct (t) | 8.48 (3.93) | 0.29 (2.17) | |
| (>€3000,- net/month, dummy) | Total (t) | 8.48 (3.93) | 1.02 (3.87) | 0.37 (2.72) |
| Low education | Direct (t) | 0.39 (1.70) | ||
| (primary, dummy) | Total (t) | 0.39 (1.70) | ||
| High education | Direct (t) | -0.36 (2.92) | ||
| (BSc or higher, dummy) | Total (t) | -0.36 (2.92) | ||
| Child(ren) in household | Direct (t) | 0.78 (2.76) | 0.28 (2.76) | |
| (dummy) | Total (t) | 0.78 (2.76) | 0.34 (3.06) | |
| Club memberships | Direct (t) | 5.22 (7.18) | ||
| (number) | Total (t) | 5.22 (7.18) | 0.63 (6.80) | 0.05 (4.72) |
| Satisfaction with neighbourhood | Direct (t) | 0.20 (3.21) | ||
| (1-5) | Total (t) | 0.20 (3.21) | ||
| Years in address | Direct (t) | 1.27 (4.24) | 0.31 (2.65) | |
| (logarithm) | Total (t) | 1.27 (4.24) | 0.41 (3.42) | |
| Neighbourhood mean income | Direct (t) | 0.15 (1.93) | ||
| (× €1000) | Total (t) | 0.15 (1.93) | 0.01 (1.85) | |
| -2ln(L) saturated model | 18,715.985 | |||
| -2ln(L) fitted model | 19,025.094 | |||
| Degrees of freedom | 45 | |||
| Chi-Square | 309.11 | |||
| Chi-Square / Degrees of Freedom | 6.87 | |||
| RMSEA | 0.13 | |||
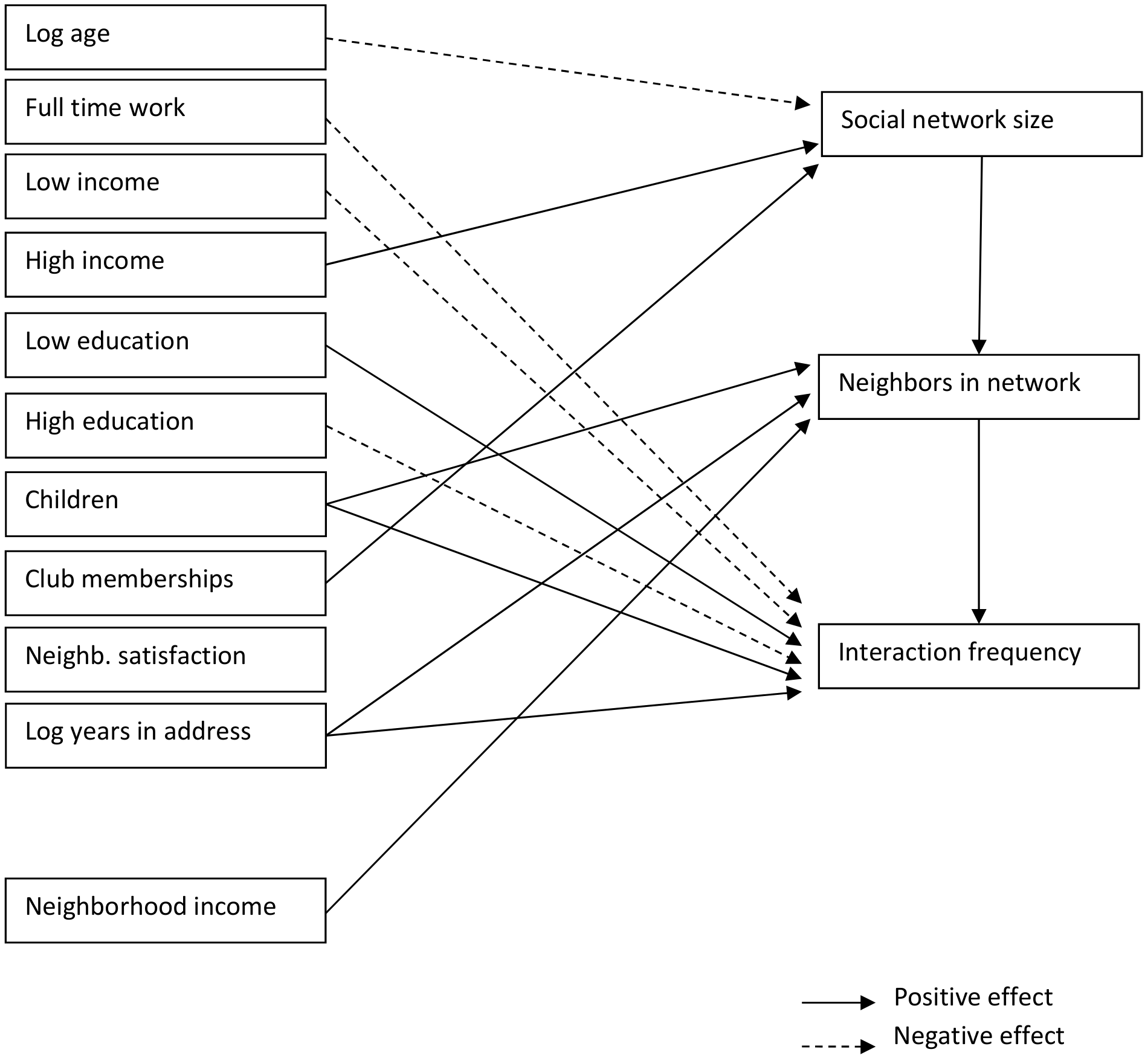
The modeling results indicate that the number of neighbors in the network is positively affected by the size of the social network. The number of neighbors in the network, in turn, has a positive effect on the frequency of interaction with neighbors. This is a plausible finding; however, the effects are only small.
Regarding the effects of socio-demographics on social network size, the results show a negative effect of age, indicating that older people have a smaller social network. This finding is in line with other studies on social networks (e.g. Van den Berg et al. 2009). High income is found to have a positive effect on social network size, which is also in line with other studies (e.g. Kowald, Axhausen 2010). Finally, the results show that involvement in clubs results in a larger social network. This is again a plausible finding, which is in line with other studies (e.g. Van den Berg et al. 2013).
The number of neighbors in a social network is found to be higher for people with children. These households tend to spend more time at home (and in the neighborhood) and are likely to get to know others in the neighborhood through their children. In the Netherlands, neighbors play an important role in caring for each other’s children (Völker, Flap 2007). Moreover, children from the same neighborhood tend to go to the same school. Parents usually wait outside in the afternoon to pick up their children. In that sense, schools “fulfil the role of meeting places where persons have the opportunity to start relationships with others” (Völker, Flap 2007, 278).
As expected, the number of years one has been living at the current address has a positive effect on the number of neighbors in the social network. This is a reasonable finding, which is in line with other studies (e.g. Van den Berg et al. 2015).
Finally, regarding the frequency of interaction with neighbors, direct effects were found for some of the socio-demographic variables. People who work full-time are found to interact with their neighbors less often. Meanwhile, less-educated people are found to have more social interactions with their neighbors and higher-educated people contact their neighbors less often. This might be related to the fact that higher educated individuals get in touch with others living further away through their studies and work. On the other hand, low income is found to reduce the frequency of interactions with neighbors. As expected, people with children are found to interact more often with their neighbors. A positive effect is also found for the number of years living at the same address and people who are more satisfied with their neighborhood (measured on a five-point Likert scale).
Gender, car ownership, and perception of social safety in the neighborhood were not found to affect any of the endogenous variables in the model. The direct effects that are significant at the 0.1 significance level in the multi-level model are shown in Figure 4.
Regarding neighborhood characteristics, a number of different variables were tested in the model, namely neighborhood income, urban density, housing tenure, residential mobility, ethnicity, household composition and age in the neighborhood, and distance to several amenities (restaurant, school, supermarket, highway, and train station). Only one of these variables was found to have a significant effect in this model: in our model, the mean income of households in the neighborhood is found to have a positive effect on the number of neighbors in the social network. This seems to support Fischer (1982) who finds that the contact frequency between neighbors is greater in higher-income neighborhoods. His explanation is that similarity between residents is higher if the average neighborhood income is higher, and similarity enhances neighborhood contacts.
Our ability to find only one of the neighborhood characteristics to significantly affect social contacts with neighbors is in contrast with our hypotheses. Although the existing literature on the relationship between neighborhood characteristics and local social contacts is scarce and inconclusive, the physical residential environment is generally assumed to play a considerable role in residents’ social contacts. Our results show that this strongly held assumption seems to be unfounded. Urban planners and policy makers should therefore be cautious regarding their expectations on the effects of modifications of neighborhood characteristics (for instance through urban renewal) on social interaction among neighbors.
5 Conclusions and discussion
Asserting that social contacts among fellow residents are important for neighborhood livability, this paper has aimed at increasing our understanding of the factors influencing neighborhood-based social contacts. Based on survey data collected in the Netherlands, a path analysis approach was used to analyze social network size and the number of neighbors in the social network, as well as the frequency of social interaction with neighbors. The exogenous variables in the model are personal socio-demographics and neighborhood characteristics.
The results indicate that socio-demographics are more important than neighborhood characteristics in explaining neighborhood-based social contact. The number of neighbors in the social network is larger for people with children and people who have been living at the current address for a longer time. These findings are in line with the literature and our hypotheses.
People with children and people who have been residing longer at the current address also have higher contact frequencies with their neighbors. Regarding socioeconomic status, the results are mixed. A higher level of education was found to have a negative effect on interaction frequency with neighbors, whereas income was found to have a positive effect.
The effects of neighborhood characteristics are limited. Our results only show a significant relationship between neighborhood income and the number of neighbors in the social network. Our finding that neighborhood characteristics only have a small impact on social contacts is inconsistent with the existing assumption that a modification of neighborhood characteristics (for instance through urban renewal) can lead to increasing social interaction among neighbors.
Although the analyzed links can help to better understand neighborhood-based social contacts, a number of aspects deserve further research. For instance, we did not differentiate between different types of social interaction with neighbors, as the data did not include this information. However, different types of interaction, such as saying “hello” in the street, borrowing items, or visiting may differ substantially in intensity and importance for people.
Moreover, the question on the number of social network members did not allow for overlap between the different categories, whereas it is possible that relatives, co-workers, or fellow club members are also neighbors. This should be kept in mind when interpreting the results for share of neighbors in the social network.
Finally, although we tested a number of neighborhood characteristics including income, urban density, housing tenure, residential mobility, ethnicity, and distance to several facilities, there might be other spatial characteristics that could affect neighborhood-based social contacts. In future research, it would be interesting to identify these characteristics, for instance by studying the role of urban form and public space for social interaction. In addition, different modeling techniques, e.g. spatial autoregressive models, could be used in future research to better capture the extent to which neighborhood characteristics affect neighborhood based social contacts.
References
Atkinson R, Kintrea K (2001) Disentangling area effects: Evidence from deprived and non-deprived neighbourhoods. Urban Studies 38: 2277–2298
Bridge G (2002) The neighbourhood and social networks. Paper 4, Centre for Neighbourhood Research. http://www.neighbourhoodcentre.org.uk
CBS – Statistics Netherlands (2012) Statline. retrieved 29-10-2012 from http://statline.cbs.nl/statweb/
Dempsey N, Brown C, Bramley G (2012) The key to sustainable urban development in UK cities? The influence of density on social sustainability. Progress in Planning 77: 89–141
Fischer CS (1982) To dwell among friends: personal networks in town and city. University of Chicago Press, Chicago
Forrest R, Kearns A (2001) Social cohesion, social capital and the neighbourhood. Urban Studies 38: 2125–2143
Francis J, Giles-Corti B, Wood L, Knuiman M (2012) Creating sense of community: The role of public space. Journal of Environmental Psychology 32: 401–409
Galster G (2007) Should policy makers strive for neighbourhood social mix? An analysis of the Western European evidence base. Housing studies 22: 523–545
Golob T (2001) Structural equation modeling for travel behaviour research. Transportation Research Part B 37: 1–25
Granovetter MS (1973) The strength of weak ties. American Journal of Sociology 78: 1360–1380
Guest AM, Wierzbicki SK (1999) Social ties at the neighbourhood level: two decades of GSS evidence. Urban Affairs Review 35: 92–111
Hickman P (2013) “Third Places” and social interaction in deprived neighbourhoods in Great Britain. Journal of Housing and the Built Environment 28: 221–236
Hipp J, Perrin AJ (2009) The simultaneous effect of social distance and physical distance on the formation of neighborhood ties. City & Community 8: 5–25
Hox J, Roberts J (Eds.) (2010) Handbook of Advanced Multilevel Analysis. Routledge Academic, New York
Jöreskog K, Sörbom D (2001) LISREL 8.5. Scientific Software International
Kleinhans R (2004) Social implications of housing diversification in urban renewal: a review of recent literature. Journal of Housing and the Built Environment 19: 367–389
Kowald M, Axhausen K (2010) The structure and spatial spread of egocentric leisure networks. Paper presented at Applications of Social Network Analysis (ASNA), Zurich, September 15–17
Kowald M, van den Berg PEW, Frei A, Carrasco JA, Arentze TA, Axhausen KW, Mok D, Timmermans HJP, Wellman B (2013) Distance patterns of personal networks in four countries: A comparative study. Journal of Transport Geography 31: 236–248
McCarty C, Killworth PD, Bernard HR, Johnsen EC, Shelley GA (2000) Comparing two methods for estimating network size. Human Organization 60: 28–39
Mollenhorst G (2014) Neighbour relations in the Netherlands: new developments. Tijdschrift voor Economische en Sociale Geografie 106: 10–119
Mollenhorst G, Völker B, Schutjens V (2009) Neighbour relations in the Netherlands. A decade of evidence. Tijdschrift voor Economische en Sociale Geografie 100: 549–558
Oldenburg R (1989) The Great Good Place. Marlow, New York
Pinkster F, Völker B (2009) Local social networks and social resources in two Dutch neighbourhoods. Housing studies 24: 225–242
Talen E (1999) The social doctrine of new urbanism. Urban Studies 36: 1361–1379
Thomése F, van Tilburg T (2000) Neighbouring networks and environmental dependency. differential effects of neighbourhood characteristics on the relative size and composition of neighbouring networks of older adults in The Netherlands. Ageing and Society 20: 55–78
Van Beckhoven E, Van Kempen R (2003) Social effects of urban restructuring: a case study in Amsterdam and Utrecht, the Netherlands. Housing Studies 18: 853–875
Van den Berg PEW, Arentze TA, Timmermans HJP (2009) Size and composition of ego-centered social networks and their effect on geographical distance and contact frequency. Transportation Research Record 2135: 1–9
Van den Berg PEW, Arentze TA, Timmermans HJP (2012) Involvement in clubs or voluntary associations, social networks and activity generation: a path analysis. Transportation 29: 843–856
Van den Berg PEW, Arentze TA, Timmermans HJP (2013) A path analysis of social networks, telecommunication and social activity-travel patterns. Transportation Research Part C 26: 256–268
Van den Berg PEW, Arentze TA, Timmermans HJP (2015) A multilevel analysis of factors influencing local social interaction. Transportation. submitted
Van der Poel MGM (1993) Delineating personal support networks. Social Networks 15: 49–70
Van Eijk G (2010) Does living in a poor neighbourhood result in network poverty? A study on local networks, locality-based relationships and neighbourhood settings. Journal of Housing and the Built Environment 25: 467–480
Völker B, Flap H (2007) Sixteen million neighbors. a multilevel study of the role of neighbors in the personal networks of the Dutch. Urban Affairs Review 43: 256–284
Washington S, Karlaftis M, Mannering F (2003) Statistical and Econometric Methods for Transportation Data Analysis. Chapman & Hall, Washington D.C.
Wellman B (1979) The community question: The intimate network of East Yorkers. American Journal of Sociology 84: 1201–1231
Wellman B (2001) Physical space and cyberspace: the rise of personalized networking. International Journal of Urban and Regional Research 25: 227–252